Gsam
Gsam is a plugin that joins Meta's Segment Anything (SAM) with GroundingDINO for prompt use. This lets you segment anything in an image or video using a text-based prompt. This lets you select anything that you might want in an image without training a new model on that object.
Usage
To use Gsam, first get an image that you want to mask. It will return a mask that you can use frame-by-frame, or by using Adobe's masking tool to continue the mask over each frame. If you have multiple instances, Gsam can be helpful to find every instance.
Gsam has a few different paramters that let you control it.
Prompt
To use the Prompt, click the button then describe the object(s) that you want masked.

Gsam will mask anything in the layer that matches the prompts. So if you want to mask multiple things,you can include all the items that you want to include in the mask in the prompt. So if you include as the prompt "Trees and bushes" it will mask both of those.
box_threshold
Box threshold filters objects based upon how similar the boxes are to the classes. Higher thresholds will filter boxes that aren't very good examples of the class. If you find that objects are found correctly, but that too much surrounding the object that you want is masked, you may want to increase this threshold.
text_threshold
text threshold filters objects based upon how similar the text of the box matches the text prompt. Higher thresholds are more picky about how accurately the objects detected match the text prompt. If you find that objects that aren't quite matching the prompt are selected, then you may want to increase this threshold to limit those inaccurate objects.
Example
Here is an example of a SuperCar that we want to mask.
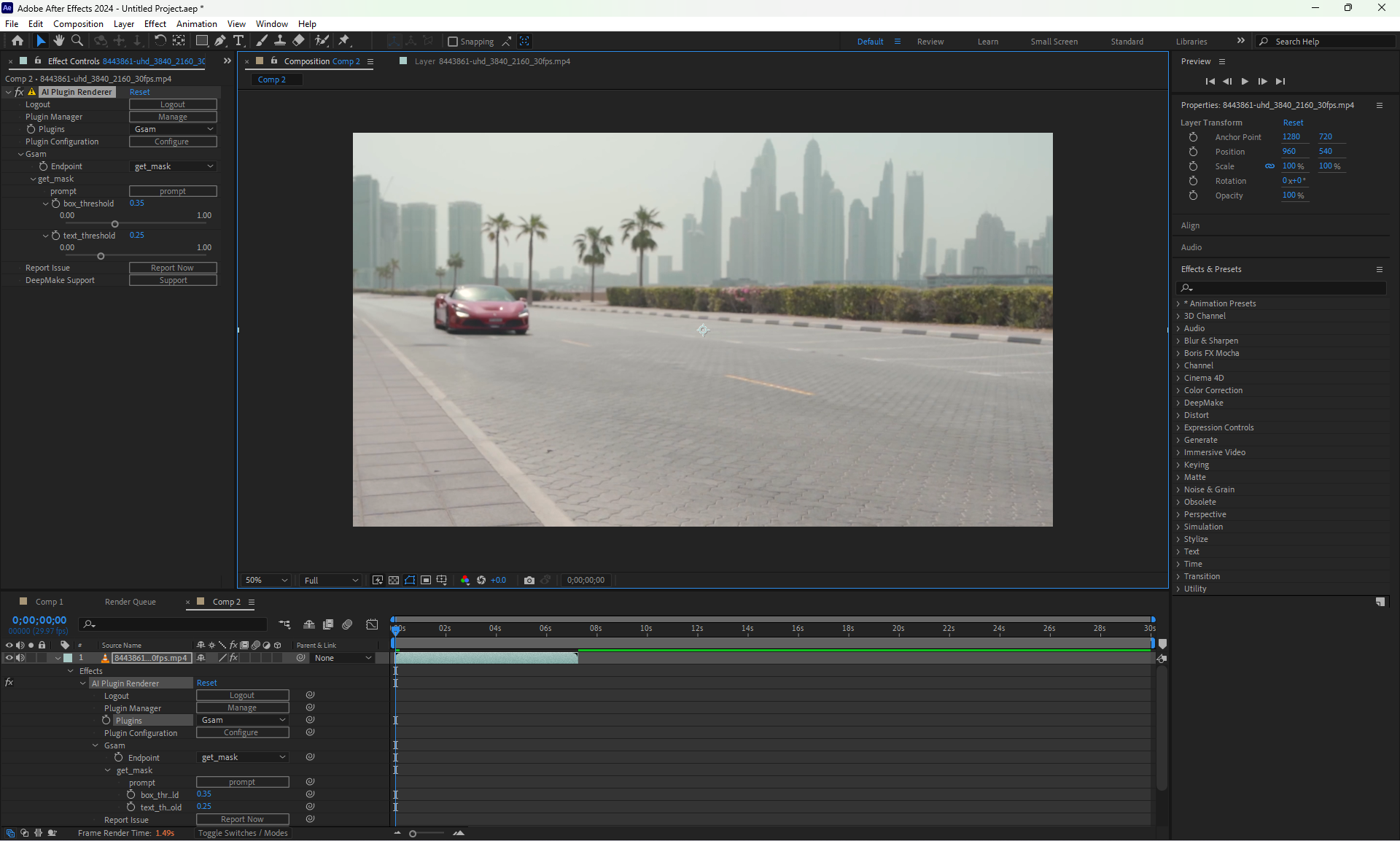
We select the prompt of "A Supercar"

After waiting, the model detects the Car and masks it out.